配置GTID主从复制(新建)
环境:
主服务器:121.4.185.xxx
从服务器:39.103.239.xx
1、准备工作 开启gtid 创建同步用户等
(2)、主服务器配置my.cnf
[root@VM-0-15-centos ~]# vim /etc/my.cnf 添加:
server_id=1
gtid_mode=on
enforce_gtid_consistency=on
log_bin=master-binlog
log-slave-updates=1
binlog_format=row
skip_slave_start=1
(3)、重启主服务器MySQL服务
[root@localhost ~]# systemctl restart mysqld
(4)、进入主服务器给从服务器授权复制权限
[root@localhost ~]# mysql -uroot -p123456
mysql> grant replication slave on *.* to 'root'@'%' identified by '123456';
(5)、从服务器配置my.cnf
[root@localhost ~]# vim /etc/my.cnf 添加:
server_id=2
gtid_mode=on
enforce_gtid_consistency=on
log-bin=slave-binlog
log-slave-updates=1
binlog_format=row
skip_slave_start=1(6)、重启从服务器MySQL服务
[root@localhost ~]# systemctl restart mysqld
2、主库备份最新的数据库
mysqldump -uroot -pxxx --default-character-set=utf8mb4 --single_transaction --master-data=2 --databases xxx > test.sql;3、清理从库机器 删除已有数据库 并且清理主从状态 stop slave; reset master; reset slave all; 同时停止从库读写
4、slave数据库导入数据 source /www/backup/test.sql;
CHANGE MASTER TO MASTER_HOST='xxx' ,,MASTER_USER='xxx' ,MASTER_PASSWORD='xxx' ,MASTER_AUTO_POSITION=1;
start slave;
show slave status\G;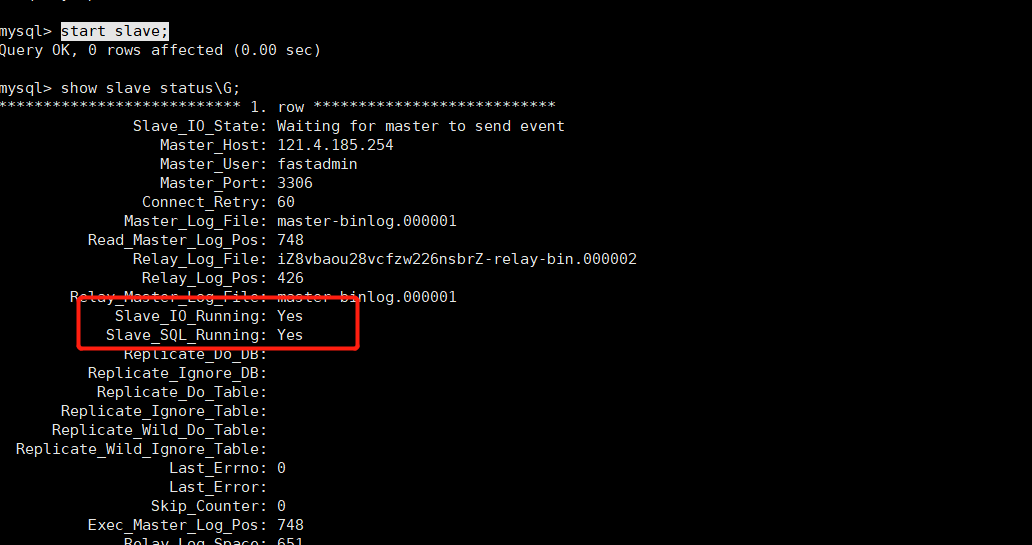
2023-03-16 02:22:32 13406 [Warning] Storing MySQL user name or password information in the master info repository is not secure and is therefore not recommended. Please consider using the USER and PASSWORD connection options for START SLAVE; see the 'START SLAVE Syntax' in the MySQL Manual for more information.
看样子是从库重新连接造成的; 我这主要是因为两个配置项造成的:
slave_net_timeout
MySQL主从复制的时候, 当Master和Slave之间的网络中断,但是Master和Slave无法察觉的情况下(比如防火墙或者路由问题)。Slave会等待slave_net_timeout设置的秒数后,才能认为网络出现故障,然后才会重连并且追赶这段时间主库的数据。
master_heartbeat_period
设置复制心跳的周期,取值范围为0 到 4294967秒。精确度可以达到毫秒,最小的非0值是0.001秒。心跳信息由master在主机binlog日志文件在设定的间隔时间内没有收到新的事件时发出,以便slave知道master是否正常。默认值为slave_net_timeout的值除以2,设置为0表示完全的禁用心跳。
如果心跳参数master_heartbeat_period大于slave_net_timeout, 且主库当前没有DML/DDL等操作, 就会导致从库每隔slave_net_timeout设置的时间后重新连接主库, 产生一条新的relay_log。
解决方法:在从库上心跳参数设置成小于slave_net_timeout:
stop slave;
change master to master_heartbeat_period = 150;
set global slave_net_timeout = 300;
start slave;


发表评论 取消回复